Signal Theory of Intelligence
for the European Union’s Human Brain Project
2.1 Elementary signals
An elementary signal is the smallest distinguishable unit of a signal system. In signal theory, it corresponds to a basis vector of a suitable vector space. Each elementary signal represents an elementary property or an elementary characteristic of a stimulus.
Formally: An elementary signal is a vector
![]() of the canonical basis
of the signal space
of the canonical basis
of the signal space
![]()
2.2 Complex signals
A complex signal is a well-ordered set of simultaneously active elementary signals. Since well-ordered sets can be uniquely represented in vector form, a complex signal corresponds to a linear combination of elementary signals.
Formally:
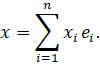
A complex signal is thus a point in signal space that represents a structured combination of elementary features.
2.3 Elementary forms and complex forms
An elementary form is the form represented by a single elementary signal. A complex form is the form represented by a complex signal.
It follows that:
- Elementary forms are atomic patterns.
- Complex forms are composite patterns consisting of elementary forms.
The form of a signal is its geometric structure in vector space.
2.4 Direct and inverse systems
A direct system maps elementary signals onto complex signals. An inverse system maps complex signals back onto elementary signals.
Formally:
- Direct system:
![]()
with![]() as
the weight matrix.
as
the weight matrix.
- Inverse system:
![]()
In the symmetric case, a single matrix![]() suffices, since the
inverse system is realised by the transpose.
suffices, since the
inverse system is realised by the transpose.
2.5 Significance of these basic concepts
These concepts allow for a precise signal-theoretical description of the processes in multi-layered network structures:
- Elementary signals form the basic building blocks.
- Complex signals are structured combinations of these building blocks.
- The direct system generates complex forms from elementary forms.
- The inverse system breaks complex forms down again into elementary forms.
- The cyclical application of both systems generates an alternation between the two forms of representation.
This alternation forms the basis for the mechanisms described later: signal completion, state formation, recursion, and thus the emergence of thought.