Signal Theory of Intelligence
for the European Union’s Human Brain Project
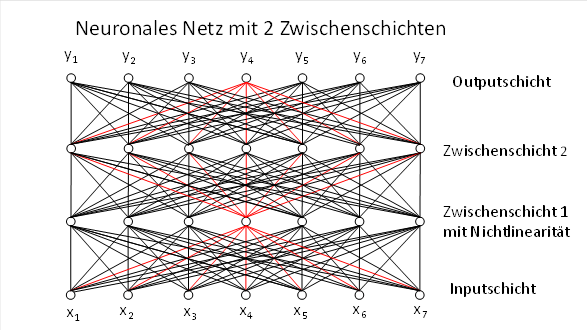
9 The introduction of a second hidden layer in neural networks
Many algorithms in artificial intelligence use network structures that have two hidden layers and are therefore described by three weight matrices. There is a very simple reason for this:
· The first layer implements signal convergence onto the intermediate neurons of the first intermediate layer. Thus, the elementary input signals are first transformed into complex signals, which are represented by the intermediate neurons of this layer.
· The second layer decomposes the complex signals back into elementary signals, whereby missing elementary signals from the original input are supplemented due to the dyadic projection. This requires that a non-linearity (lateral inhibition, ReLU, Softmax, sigmoid, Tanh or WTA) be applied to each hidden neuron in the first hidden layer in order to suppress weaker dyadic products and emphasise stronger ones.
· The third network layer forms new complex signals from the completed elementary signals. This applies particularly to AI algorithms that involve the recognition of complex signals, such as transformers or state space models.
Intelligence does not arise by chance. It is based on three fundamental processing steps that occur in virtually all intelligence-generating systems – regardless of whether they are transformers, state space models or biological neural networks. These systems always carry out the same sequence:
1. Elementary signals are converted into complex signals.
2. Complex signals are broken down into their elementary signals, with missing components being added and noisy components being corrected.
3. The elementary signals thus completed are transformed back into new complex signals.
Since complex signals can be represented vectorially and their components form elementary signals, working with them inevitably leads to algebra and matrix operations. This is why both biological and artificial neural networks require three independent weight matrices to map these three steps.
In transformers, these matrices are called query, key and value. They define the three linear mappings that make up the so-called attention mechanism. Yet behind this terminology lies a universal principle that extends far beyond transformers.
9.1 Universal theorem of triple projection
Every intelligent signal analysis system requires three independent linear mappings to link input, internal state and output.
These three mappings fulfil universal functions:
9.1.1 Input projection
A matrix transforms external signals into an internal state or feature space.
- Transformer:
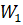
- State Space Models:
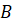
- Biology: Cortex → Basal ganglia
9.1.2 Decomposition and completion
A matrix decomposes complex signals into their elementary signals and supplements missing components.
- Transformer:
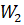
- State Space Models:
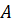
- Biology: Basal ganglia → Cerebellum
9.1.3 Output projection
A matrix transforms the completed elementary signals back into new complex signals.
- Transformer:
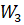
- State Space Models:
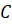
- Biology: Cerebellum → Thalamus/Cortex
This three-part structure is architecture-independent. It occurs equally in discrete, continuous, recurrent and biological systems.
Neural systems operate in the original data domain. Transformers, on the other hand, operate in the image domain. This difference is technical in nature and has evolved historically.
9.2 Theorem of the emergence of intelligence
Intelligence arises when a system projects input into a state, decomposes this state into its elementary signals and completes it, and then projects new complex signals as output from this. Exactly three independent weight matrices are necessary – and sufficient – for this.
Why does a three-stage system generate intelligence?
In the AI community, this question is rarely asked and practically never answered. Instead, reference is made to the ‘attention mechanism’, which is formally correct but offers little in the way of explanation. However, the intelligence-generating property of transformers and related architectures arises from a simple, deep structure:
Three linear mappings, combined with non-linearities, are sufficient to form, decompose, complete and recombine patterns – even when they are only partially present in the input.
This brings us to the central result.
9.3 First theorem of the minimal architecture of intelligence-generating systems
A fully connected network with two hidden layers and three independent weight matrices: Query (Q), Key (K) and Value (V)
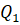 : Input layer – elementary
signals → Intermediate layer 1 – complex signals
: Input layer – elementary
signals → Intermediate layer 1 – complex signals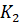 : Intermediate layer 1 –
complex signals → Intermediate layer 2 – elementary signals with
signal completion
: Intermediate layer 1 –
complex signals → Intermediate layer 2 – elementary signals with
signal completion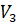 : Intermediate layer 2 –
elementary signals → output layer – new complex signals
: Intermediate layer 2 –
elementary signals → output layer – new complex signals
and Hebbian-style learning in the two hidden layers, as well as non-linearity, possesses the following properties:
1. Formation of complex signals from elementary signals
The first
hidden layer learns the most frequent input patterns![]() as complex signals via
Hebb/LTP/LTD. Each hidden neuron represents one such complex signal.
as complex signals via
Hebb/LTP/LTD. Each hidden neuron represents one such complex signal.
2. Complex signal decomposition with completion
The second intermediate layer decomposes each complex signal back into its elementary signals. In doing so, it supplements missing components and corrects noisy components. However, it is necessary that those dyadic summands of the intermediate neurons whose output is too weak are suppressed by a non-linearity.
3. Pattern completion
If a corrupted input is presented to the second intermediate layer
![]()
, the network generates an output
![]()
that differs from the ideal complex signal only by a scalar factor.
· Missing components are supplemented,
· overly strong components are reduced proportionally,
· and the direction of the complex signal is preserved.
The system thus reconstructs the complete pattern from an incomplete or noisy input.
4. Intelligence-generating property
The system generates complete complex signals from incomplete or noisy inputs. It reconstructs, completes and stabilises patterns that are not fully present in the input.
The supplemented or corrected elementary signals constitute new information generated by the system itself. At the next network level, they can be combined with other elementary signals to form new complex signals that did not exist in the original input either.
This ability to supplement and form new patterns is the core of intelligence.
Whether a signal is to be interpreted as an elementary signal or a complex signal is often a matter of opinion. Therefore, an alternative interpretation of the theorem of the emergence of intelligence is also possible.
9.4 Second Theorem of the Origin of Intelligence
Intelligence arises when a system transforms complex signal input into its elementary form and completes it, transfers this state back into its complex form, and generates new elementary signals as output from it. For this, exactly three independent weight matrices and a non-linearity are necessary – and sufficient.
The cause of intelligence is therefore not the conversion of the elementary form into the complex form or vice versa, but the signal supplementation that occurs in the process, whereby the system inevitably creates new input that was not present in the original input at all.
Bibliography:
The author arrived at this insight as early as 2012 in his monograph “Theory of the Neural Circuitry of the Brain and Analytical Thinking”, in the chapter “Part 2.15. The Emergence of Consciousness and Thought as a Systems-Theoretical Reality”, published under ISBN 978-3-00-037458-6 and available online at https://www.andreas-malczan.de/Monografie_Teil_1_und_2.html in the chapter https://www.andreas-malczan.de/teil-2-15.html.