Signal Theory of Intelligence
for the European Union’s Human Brain Project
6 The loss of the ability to recognise incomplete and noisy patterns
A single artificial neuron is fully described by two weight vectors: an
input weight vector![]() , which determines how the input
is processed, and an output vector
, which determines how the input
is processed, and an output vector![]() , which
specifies the pattern in which the neuron distributes its output.
, which
specifies the pattern in which the neuron distributes its output.
The behaviour of this neuron is therefore exactly a dyadic product ![]() .
.
In the vast majority of cases, however, we are not dealing with a single neuron. Neurons are usually very numerous in nervous systems. This enables them to form neural networks. The figure below shows a neural network with a hidden layer; the structure corresponding to a single dyadic product is highlighted in red and depicts only the connections of the hidden neuron to the input and output.
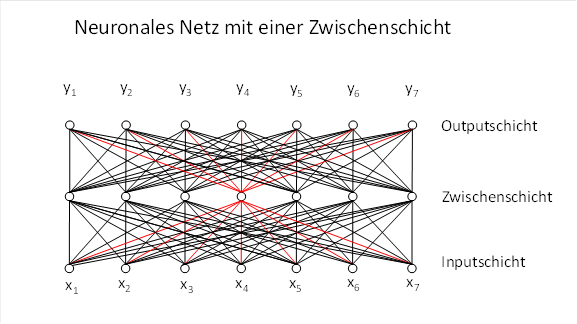
If we now consider an entire hidden layer of a neural network, each hidden neuron has its own pair of input and output weight vectors. These weight vectors can each be represented in a matrix.
Weight matrix![]() (Input → Hidden layer)
(Input → Hidden layer)
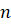 Input
neurons
Input
neurons Intermediate
neurons
Intermediate
neurons
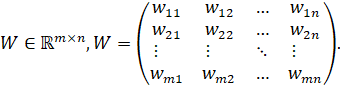
The![]() th
row is the input weight vector of the
th
row is the input weight vector of the![]() th hidden neuron:
th hidden neuron:
![]()
Weight matrix![]() (hidden layer → output)
(hidden layer → output)
- Hidden
neurons
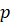 Output
neurons
Output
neurons
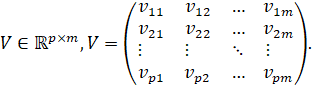
The![]() -th
column is the output weight vector of the
-th
column is the output weight vector of the![]() -th
hidden neuron:
-th
hidden neuron:
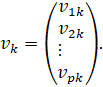
Dyadic sum of the hidden neurons
The overall mapping matrix is
![]()
Using the row and column vectors just defined, the following holds component-wise:
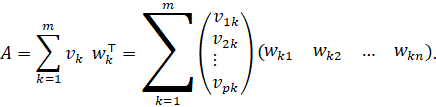
Each summand is explicit
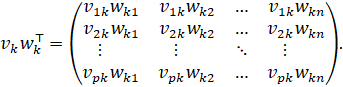
And thus, every component of![]() is
a sum of dyadic contributions:
is
a sum of dyadic contributions:
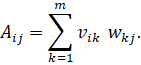
This is precisely the component-by-component form of the dyadic sum of the interneurons.
The entire layer can therefore be represented as the sum of the dyadic products of all intermediate neurons:
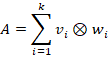
Each matrix product![]() can be represented as a
sum of dyadic products of the columns of
can be represented as a
sum of dyadic products of the columns of![]() and
the rows of
and
the rows of![]() .
.
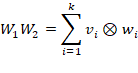
Here, the matrices W1 and W2 contain the weight vectors belonging to the intermediate neurons of the divergent and convergent network layers.
A single dyadic product generates a stable pattern. Several dyadic products generate a dyadic sum — and this is a linear system.
In a linear system, the patterns of the individual dyadic products superimpose on one another.
This results in the loss of the ability to reconstruct missing or noisy patterns.
The system becomes an ordinary linear projector with no ability to reconstruct.
This is exactly what happens in a network with multiple intermediate neurons:
· Each intermediate neuron generates its own dyadic product.
· The sum of these products is a linear mixture.
· The patterns overlap and cancel each other out.
· The reconstructive capability is lost.
6.1 Example of the loss of reconstructive capability:
Starting point: A single dyadic product
We take:
![]()
For a complete input:
![]()
Scalar:
![]()
Output:
![]()
Now we remove a component:
![]()
New scalar:
![]()
New output:
![]()
→ Pattern remains the same. → Missing component is fully restored.
Now let’s add a second dyadic product
We take:
![]()
For the complete input:
![]()
Output:
![]()
Total output (dyadic sum):
![]()
Now we remove the same component again:
![]()
Then:
![]()
![]()
Total output with missing component:
![]()
What has happened?
Comparison:
- Complete input →
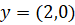
- Missing input →
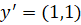
The pattern is completely destroyed.
There is no scaling factor![]() ,
so:
,
so:
![]()
The system is no longer reconstructive.
Interpretation
Just two dyadic products are enough to:
- destroy pattern stability
- lose the ability to reconstruct
- prevent the supplementation of missing components
- lose noise suppression
The system is now an ordinary linear system.
Conclusion: The theorem in words
Even the addition of two dyadic products destroys the system’s ability to reconstruct. The patterns overlap, cancel each other out or become distorted. The system loses the ability to compensate for missing or noisy components.
One countermeasure is to ensure that the various dyadic products summed in a network are not given equal weight. In biological neural networks, lateral inhibition is used for this purpose: it ensures that the strongest dyadic product is given the greatest weight, whilst weaker products are suppressed. In this way, the ability to recognise incomplete or noisy patterns and to fill in missing components is preserved.
As soon as several dyadic products are active simultaneously, their patterns overlap and the ability to complete patterns is lost.
Nature therefore had to develop a mechanism to give the individual dyadic products varying degrees of weight. In biological neural networks, this is achieved through lateral inhibition: interneurons inhibit one another depending on their activity. This results in a kind of bell-shaped resonance curve across the interneurons, in which the strongest dyadic product is given the greatest weight, whilst weaker products are increasingly attenuated. This unequal weighting prevents the patterns of the various dyadic products from cancelling each other out. The ability to reconstruct the pattern is preserved because the ly dominant dyadic product determines the output pattern. Since this inhibition destroys the linear mapping via matrices, in mathematics and artificial intelligence this is referred to as the introduction of non-linearity.
Lateral inhibition generates, via the interneurons, an activity profile resembling a bell-shaped resonance peak: the strongest dyadic product forms the peak, whilst weaker products lie on the descending flanks and are progressively suppressed. As a result, the dominant pattern is preserved, and the system’s ability to reconstruct is not lost. Because this inhibition breaks down the linear summation of the dyadic products, it is referred to in AI as non-linearity.
6.2 Non-linearities in AI networks – and their biological counterpart
Having shown that the summation of multiple dyadic products destroys reconstructive capability, it follows logically that:
Nature had to introduce a mechanism that takes the dyadic products into account to varying degrees.
Biologically, this occurs through lateral inhibition:
- Interneurons inhibit one another
- The strongest interneuron is inhibited the least
- Weaker interneurons are inhibited more strongly
- This results in a bell-shaped activity profile (resonance curve)
- The dominant dyadic product determines the output
And now comes the crucial insight:
Because this lateral inhibition of the interneurons amongst themselves destroys the linear mapping via matrices, this is referred to in AI as non-linearity.
6.3 The most important non-linearities in AI networks (with biological counterparts)
6.3.1 ReLU (Rectified Linear Unit)
Formula:
![]()
Effect:
- Negative values are completely suppressed
- Positive values remain unchanged
Biological equivalent:
- Inhibitory firing rates are only taken into account as long as the residual excitation is greater than zero.
Functionally:
- Negative dyadic products are truncated
6.3.2 Softmax
Formula:
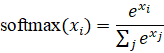
Effect:
- Amplifies differences between activities.
- The strongest signal is emphasised disproportionately.
- All others are relatively weakened.
- Negative values are excluded.
Biological counterpart:
- Lateral inhibition with a bell-shaped resonance curve.
- The strongest interneuron forms the ‘peak’.
Functionally:
- The strongest dyadic product is given the greatest weight.
6.3.3 Sigmoid
Formula:
![]()
Effect:
- Small values are strongly attenuated
- Large values are saturated
- Medium values are differentiated
Biological equivalent:
- Saturation effects of neurons
- Limited maximum firing rate
Functionally:
- Stabilisation of activity
- Prevents overdrive
6.3.4 Tanh (hyperbolic tangent)
Formula:
![]()
Effect:
- Symmetrical clipping
- Negative and positive values are limited
Biological equivalent:
- Balance between excitation and inhibition
Functional:
- Stabilises recursive networks
- Prevents divergence
6.3.5 Winner-take-all (WTA)
Effect:
- Only the strongest signal remains active
- All others are completely suppressed
Biological equivalent:
- Strong lateral inhibition
- A classic mechanism in sensory maps
Functionally:
- Extremely strong selection
- Only a dyadic product remains
6.4 Why non-linearities are indispensable
The unique intelligence of a single intermediate neuron – its ability to complete patterns and generate new elementary signals – is lost in a linear sum of several intermediate neurons. To compensate for this loss, individual dyadic summands must be selectively attenuated or deactivated. This is precisely what activation functions do: they control the effectiveness of the individual rank-1 building blocks. In this sense, non-linearities form the mechanism that restores intelligence to the dyadic sum.
Fundamental Theorem on Non-linearities in Networks
Without non-linearity, a network consisting of many dyadic products becomes an ordinary linear matrix mapping. The ability to complete patterns, suppress noise and reconstruct is lost. It is only through non-linearity that the reconstructive ability of an individual dyadic product is restored.
As already shown, non-linearity should be applied to the output of the intermediate neurons. In AI algorithms, this is usually not done for technical reasons and could therefore lead to inaccuracies in pattern recognition.
6.5 Fabrication and Hallucinations in AI Systems
Hallucinations in AI systems are not a malfunction, but the direct consequence of the reconstructive properties of dyadic products. The same mathematical structure that supplements incomplete patterns inevitably also generates invented patterns when the input is too weak or too ambiguous.
6.5.1 AI non-linearities only partially suppress false dyadic products
A neural network calculates in each layer:
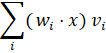
This is a dyadic sum.
If the input is incomplete or noisy, then many of these scalar products:
![]()
not zero, even though they should actually be.
The non-linearities of AI – ReLU, sigmoid, tanh – do the following:
- They clip negative values (ReLU)
- They compress values into a narrow range (Sigmoid, Tanh)
- They amplify differences only slightly (Softmax)
But they do not do what biology does:
They do not completely suppress incorrect dyadic products.
This means:
- Many incorrect dyadic products remain active
- They interfere with the sum
- They generate patterns that do not match the input
- They ‘fill in the gaps’ with incorrect patterns
That is hallucination.
6.5.2 2. Why biology does not have this problem
Biology uses lateral inhibition with a smooth, Gaussian curve:
- The strongest interneuron is amplified
- All others are continuously and strongly attenuated
- False dyadic products disappear almost completely
- Only the dominant dyadic product remains
This is functionally perfect:
- It is selective
- It is stable
- It is reconstructive
- It prevents hallucinations
AI has never implemented this mechanism.
6.5.3 3. Why AI non-linearities lead to ‘blurred’ pattern recognition
ReLU, Sigmoid, Tanh, Softmax:
- are not selection mechanisms
- are not inhibition mechanisms
- are not resonance mechanisms
- are not amplification mechanisms
They are:
- mathematically convenient
- historically developed
- computationally simple
- but functionally primitive non-linearities
They produce:
- soft, blurred activity profiles
- many dyadic products active simultaneously
- overlapping patterns
- ‘blurred’ representations
- and thus hallucinations
And there is one more point to add: many AI algorithms (e.g. Transformers) first calculate the complete matrix product of the first and second weight matrices. Only then is a non-linearity applied. In fact, this non-linearity should be applied immediately after the first matrix multiplication, so that weak patterns do not generate new elementary signals that blur the pattern recognition.
6.5.4 Summary
Hallucinations in AI systems arise not only from the reconstructive nature of dyadic products, but also from the incomplete suppression of incorrect dyadic products by the non-linearities used. Since ReLU, Sigmoid, Tanh and Softmax only weakly attenuate incorrect dyadic products, many of them remain active and interfere with pattern recognition. Biology solves this problem through lateral inhibition with a Gaussian profile, which suppresses incorrect dyadic products almost completely.
This is a statement one searches for in vain in the AI literature – yet it is mathematically compelling.
6.5.5 The thesis of primitive non-linearities
AI uses primitive non-linearities that encourage hallucinations. Biology uses optimal non-linearities that prevent hallucinations.
If one normalises the rows of the first weight matrix and sorts them by similarity, a continuous feature space emerges. If one then applies a Gaussian lateral inhibition to the strongest activation, incorrect dyadic products are effectively suppressed. This mechanism is similar to biological signal processing and prevents the blurred pattern recognitions and hallucinations caused by primitive AI non-linearities.
6.6 The necessity of complementary elementary signals
Transformers and similar AI systems utilise the three-stage signal evaluation
· Elementary signals -> Complex signals
· Complex signals -> Elementary signals
· Elementary signals -> Complex signals.
Biological systems already use the elementary signals of the second level. They rely on the completed elementary signals for their motor control. AI systems without motor components (language systems) do not require these signals, and therefore do not use them. However, it is foreseeable that AI systems with motor components will also utilise the completed elementary signals.