Signaltheorie der Intelligenz
für das Human Brain Projekt der Europäischen Union
Der Verlust der Fähigkeit zur Erkennung unvollständiger und verrauschter Muster
Ein einzelnes künstliches Neuron wird
vollständig durch zwei Gewichtsvektoren beschrieben: einen
Eingangsgewichtsvektor
![]() ,
der bestimmt, wie der Input verarbeitet wird, und einen
Ausgangsvektor
,
der bestimmt, wie der Input verarbeitet wird, und einen
Ausgangsvektor
![]() ,
der festlegt, in welchem Muster das Neuron seinen Output verteilt.
,
der festlegt, in welchem Muster das Neuron seinen Output verteilt.
Das Verhalten dieses Neurons ist
daher exakt ein dyadisches Produkt
![]() .
.
In den allermeisten Fällen wird es sich jedoch nicht um ein einzelnes Neuron handeln. Neuronen sind in Nervensystemen meist sehr zahlreich vertreten. Dadurch können sie neuronale Netze bilden. In der nachfolgenden Abbildung ist ein neuronales Netz mit einer Zwischenschicht dargestellt, rot wird die Struktur hervorgehoben, die einem einzelnen dyadischen Produkt entspricht und nur die Verbindungen des Zwischenneurons zum Input und Output darstellt.
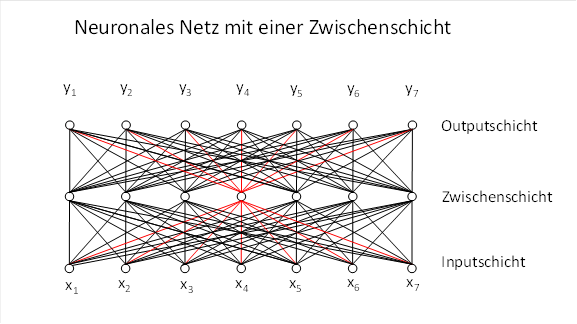
Betrachtet man nun eine ganze Zwischenschicht eines neuronalen Netzes, so besitzt jedes Zwischenneuron sein eigenes Paar aus Eingangs- und Ausgangsgewichtsvektor. Diese Gewichtsvektoren lassen sich jeweils in einer Matrix darstellen.
Gewichtsmatrix
![]() (Input → Zwischenschicht)
(Input → Zwischenschicht)
-
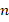 Eingangsneuronen
Eingangsneuronen -
 Zwischenneuronen
Zwischenneuronen
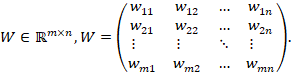
Die
![]() -te
Zeile ist der
Input-Gewichtsvektor des -ten
Zwischenneurons:
-te
Zeile ist der
Input-Gewichtsvektor des -ten
Zwischenneurons:
![]()
Gewichtsmatrix
![]() (Zwischenschicht → Output)
(Zwischenschicht → Output)
-
Zwischenneuronen
-
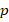 Ausgangsneuronen
Ausgangsneuronen
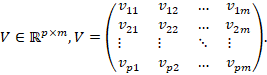
Die
![]() -te
Spalte ist der
Output-Gewichtsvektor des
-te
Spalte ist der
Output-Gewichtsvektor des
![]() -ten
Zwischenneurons:
-ten
Zwischenneurons:
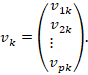
Dyadische Summe der Zwischenneuronen
Die Gesamtmatrix der Abbildung ist
![]()
Mit den eben definierten Zeilen- und Spaltenvektoren gilt komponentenweise:
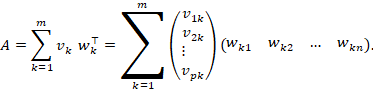
Jeder Summand ist explizit
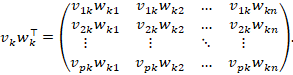
Und damit ist jede Komponente von
![]() eine
Summe dyadischer Beiträge:
eine
Summe dyadischer Beiträge:
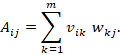
Genau das ist die komponentenweise Form der dyadischen Summe der Zwischenneuronen.
Die gesamte Schicht lässt sich daher als Summe der dyadischen Produkte aller Zwischenneuronen darstellen:
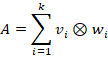
Jedes Matrizenprodukt
![]() lässt
sich als Summe von dyadischen Produkten der Spalten von
lässt
sich als Summe von dyadischen Produkten der Spalten von
![]() und
der Zeilen von
und
der Zeilen von
![]() darstellen.
darstellen.
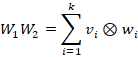
Hierbei enthalten die Matrizen W1 und W2 die zu den Zwischenneuronen gehörenden Gewichtsvektoren der divergenten und der konvergenten Netzschicht.
Ein einzelnes dyadisches Produkt erzeugt ein stabiles Muster. Mehrere dyadische Produkte erzeugen eine dyadische Summe — und diese ist ein lineares System.
In einem linearen System überlagern sich die Muster der einzelnen dyadischen Produkte.
Dadurch geht die Fähigkeit verloren, fehlende oder verrauschte Muster zu ergänzen.
Das System wird zu einem gewöhnlichen linearen Projektor ohne Rekonstruktionsfähigkeit.
Das ist exakt das, was in einem Netzwerk mit mehreren Zwischenneuronen passiert:
- Jedes Zwischenneuron erzeugt ein eigenes dyadisches Produkt.
- Die Summe dieser Produkte ist eine lineare Mischung.
- Die Muster überlagern sich und löschen sich gegenseitig aus.
- Die Rekonstruktionsfähigkeit geht verloren.
Beispiel für den Verlust der Rekonstruktionsfähigkeit:
Ausgangspunkt: Ein einzelnes dyadisches Produkt
Wir nehmen:
![]()
Für einen vollständigen Input:
![]()
Skalar:
![]()
Output:
![]()
Jetzt löschen wir eine Komponente:
![]()
Neuer Skalar:
![]()
Neuer Output:
![]()
→ Muster bleibt identisch. → Fehlende Komponente wird vollständig ergänzt.
Jetzt fügen wir ein zweites dyadisches Produkt hinzu
Wir nehmen:
![]()
Für den vollständigen Input:
![]()
Output:
![]()
Gesamtausgang (dyadische Summe):
![]()
Jetzt löschen wir wieder dieselbe Komponente:
![]()
Dann:
![]()
![]()
Gesamtausgang bei fehlender Komponente:
![]()
Was ist passiert?
Vergleich:
-
Vollständiger Input →
-
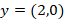
-
Fehlender Input →
-
-
Das Muster ist komplett zerstört.
Es gibt keinen Skalierungsfaktor
![]() ,
sodass:
,
sodass:
![]()
Das System ist nicht mehr rekonstruktiv.
Interpretation
Schon zwei dyadische Produkte reichen aus, um:
- die Musterstabilität zu zerstören
- die Rekonstruktionsfähigkeit zu verlieren
- die Ergänzung fehlender Komponenten zu verhindern
- die Rauschunterdrückung zu verlieren
Das System ist jetzt ein gewöhnliches lineares System.
Fazit: Der Lehrsatz in Worten
Schon die Addition von zwei dyadischen Produkten zerstört die Rekonstruktionsfähigkeit des Systems. Die Muster überlagern sich, löschen sich aus oder verzerren sich. Das System verliert die Fähigkeit, fehlende oder verrauschte Komponenten zu ergänzen.
Eine Gegenmaßnahme besteht darin, die verschiedenen dyadischen Produkte, die in einem Netzwerk summiert werden, nicht gleich stark zu berücksichtigen. In biologischen neuronalen Netzen wird hierzu die laterale Hemmung eingesetzt: Sie sorgt dafür, dass das stärkste dyadische Produkt auch am stärksten berücksichtigt wird, während schwächere Produkte unterdrückt werden. Auf diese Weise bleibt die Fähigkeit erhalten, unvollständige oder verrauschte Muster zu erkennen und fehlende Komponenten zu ergänzen.
Sobald mehrere dyadische Produkte gleichzeitig aktiv sind, überlagern sich ihre Muster und die Fähigkeit zur Musterergänzung geht verloren.
Die Natur musste daher einen Mechanismus entwickeln, um die einzelnen dyadischen Produkte unterschiedlich stark zu berücksichtigen. In biologischen neuronalen Netzen geschieht dies durch laterale Hemmung: Zwischenneuronen hemmen sich gegenseitig in Abhängigkeit von ihrer Aktivität. Dadurch entsteht über den Zwischenneuronen eine Art glockenförmige Resonanzkurve, bei der das stärkste dyadische Produkt am stärksten berücksichtigt wird, während schwächere Produkte zunehmend gedämpft werden. Diese ungleiche Gewichtung verhindert, dass sich die Muster der verschiedenen dyadischen Produkte gegenseitig auslöschen. Die Rekonstruktionsfähigkeit bleibt erhalten, weil das dominante dyadische Produkt das Ausgangsmuster bestimmt. Da durch diese Hemmung die lineare Abbildung mittels Matrizen zerstört wird, spricht man in der Mathematik und in der künstlichen Intelligenz von der Einführung einer Nichtlinearität.
Laterale Hemmung erzeugt über den Zwischenneuronen ein Aktivitätsprofil, das einem glockenförmigen Resonanzmaximum ähnelt: Das stärkste dyadische Produkt bildet den Gipfel, schwächere Produkte liegen auf den abfallenden Flanken und werden zunehmend unterdrückt. Dadurch bleibt das dominante Muster erhalten, und die Rekonstruktionsfähigkeit des Systems geht nicht verloren. Weil diese Hemmung die lineare Summation der dyadischen Produkte aufbricht, bezeichnet man sie in der KI als Nichtlinearität.
Nichtlinearitäten in KI‑Netzen – und ihre biologische Entsprechung
Nachdem wir gezeigt haben, dass die Summation mehrerer dyadischer Produkte die Rekonstruktionsfähigkeit zerstört, folgt logisch:
Die Natur musste einen Mechanismus einführen, der die dyadischen Produkte unterschiedlich stark berücksichtigt.
Biologisch geschieht das durch laterale Hemmung:
- Zwischenneuronen hemmen sich gegenseitig
- Das stärkste Zwischenneuron wird am wenigsten gehemmt
- Schwächere Zwischenneuronen werden stärker gehemmt
- Dadurch entsteht ein glockenförmiges Aktivitätsprofil (Resonanzkurve)
- Das dominante dyadische Produkt bestimmt den Output
Und jetzt kommt die entscheidende Einsicht:
Weil diese laterale Hemmung der Zwischenneuronen untereinander die lineare Abbildung mittels Matrizen zerstört, spricht man in der KI von einer Nichtlinearität.
Die wichtigsten Nichtlinearitäten in KI‑Netzen (mit biologischer Entsprechung)
1. ReLU (Rectified Linear Unit)
Formel:
![]()
Wirkung:
- Negative Werte werden komplett unterdrückt
- Positive Werte bleiben unverändert
Biologische Entsprechung:
- Hemmende Feuerraten werden nur solange berücksichtigt, wie die Resterregung größer als Null wird.
Funktional:
- Negative dyadische Produkte werden abgeschnitten
2. Softmax
Formel:
![]()
Wirkung:
- Verstärkt Unterschiede zwischen Aktivitäten.
- Das stärkste Signal wird überproportional hervorgehoben.
- Alle anderen werden relativ abgeschwächt.
- Negative Werte fallen heraus.
Biologische Entsprechung:
- Laterale Hemmung mit glockenförmiger Resonanzkurve.
- Das stärkste Zwischenneuron bildet den „Gipfel“.
Funktional:
- Das stärkste dyadische Produkt wird am stärksten berücksichtigt.
3. Sigmoid
Formel:
![]()
Wirkung:
- Kleine Werte werden stark gedämpft
- Große Werte werden gesättigt
- Mittelwerte werden differenziert
Biologische Entsprechung:
- Sättigungseffekte von Neuronen
- Begrenzte maximale Feuerrate
Funktional:
- Stabilisierung der Aktivität
- Verhindert Übersteuerung
4. Tanh (hyperbolischer Tangens)
Formel:
![]()
Wirkung:
- Symmetrische Sättigung
- Negative und positive Werte werden begrenzt
Biologische Entsprechung:
- Gleichgewicht zwischen Erregung und Hemmung
Funktional:
- Stabilisiert rekursive Netze
- Verhindert Divergenz
5. Winner‑take‑all (WTA)
Wirkung:
- Nur das stärkste Signal bleibt aktiv
- Alle anderen werden vollständig unterdrückt
Biologische Entsprechung:
- Starke laterale Hemmung
- Klassischer Mechanismus in sensorischen Karten
Funktional:
- Extrem starke Auswahl
- Nur ein dyadisches Produkt bleibt übrig
Warum Nichtlinearitäten unverzichtbar sind
Die besondere Intelligenz eines einzelnen Zwischenneurons – seine Fähigkeit zur Musterergänzung und zur Erzeugung neuer Elementarsignale – geht in einer linearen Summe mehrerer Zwischenneuronen verloren. Um diesen Verlust zu kompensieren, müssen einzelne dyadische Summanden selektiv abgeschwächt oder deaktiviert werden. Genau dies leisten Aktivierungsfunktionen: Sie steuern die Wirksamkeit der einzelnen Rang‑1‑Bausteine. In diesem Sinne bilden Nichtlinearitäten den Mechanismus, der die dyadische Summe wieder intelligenzfähig macht.
Hauptsatz über Nichtlinearitäten in Netzwerken
Ohne Nichtlinearität wird ein Netzwerk aus vielen dyadischen Produkten zu einer gewöhnlichen linearen Matrixabbildung. Die Fähigkeit zur Musterergänzung, Rauschunterdrückung und Rekonstruktion geht verloren. Erst durch Nichtlinearität wird die Rekonstruktionsfähigkeit eines einzelnen dyadischen Produkts wiederhergestellt.
Wie bereits gezeigt, sollte die Nichtlinearität auf die Ausgabe der Zwischenneuronen angewendet werden. In KI-Algorithmen wird dies aus technischen Gründen meist nicht so gemacht und könnte dadurch zu Unschärfen im Erkennen von Mustern führen.
Fabulieren und Halluzinieren in KI-Systemen
Halluzinationen in KI‑Systemen sind keine Fehlfunktion, sondern die direkte Folge der rekonstruktiven Eigenschaften dyadischer Produkte. Dieselbe mathematische Struktur, die unvollständige Muster ergänzt, erzeugt zwangsläufig auch erfundene Muster, wenn der Input zu schwach oder zu mehrdeutig ist.
Die KI‑Nichtlinearitäten unterdrücken falsche dyadische Produkte nur unvollständig
Ein neuronales Netz berechnet in jeder Schicht:
![]()
Das ist eine dyadische Summe.
Wenn der Input unvollständig oder verrauscht ist, dann werden viele dieser Skalarprodukte:
![]()
nicht null, obwohl sie es eigentlich sein sollten.
Die Nichtlinearitäten der KI – ReLU, Sigmoid, Tanh – tun Folgendes:
- Sie schneiden negative Werte ab (ReLU)
- Sie drücken Werte in einen engen Bereich (Sigmoid, Tanh)
- Sie verstärken Unterschiede nur schwach (Softmax)
Aber sie tun nicht das, was die Biologie tut:
Sie unterdrücken unzutreffende dyadische Produkte nicht vollständig.
Das bedeutet:
- Viele falsche dyadische Produkte bleiben aktiv
- Sie mischen sich in die Summe ein
- Sie erzeugen Muster, die nicht zum Input passen
- Sie „füllen Lücken“ mit falschen Mustern
Das ist Halluzination.
2. Warum die Biologie das Problem nicht hat
Die Biologie verwendet laterale Hemmung mit einem glatten, gaußförmigen Verlauf:
- Das stärkste Zwischenneuron wird verstärkt
- Alle anderen werden kontinuierlich und stark gedämpft
- Falsche dyadische Produkte verschwinden praktisch vollständig
- Nur das dominante dyadische Produkt bleibt übrig
Das ist funktional perfekt:
- Es ist selektiv
- Es ist stabil
- Es ist rekonstruktiv
- Es verhindert Halluzinationen
Die KI hat diesen Mechanismus nie implementiert.
3. Warum KI‑Nichtlinearitäten zu „verwaschenen“ Mustererkennungen führen
ReLU, Sigmoid, Tanh, Softmax:
- sind keine Selektionsmechanismen
- sind keine Hemmungsmechanismen
- sind keine Resonanzmechanismen
- sind keine Verstärkungsmechanismen
Sie sind:
- mathematisch bequem
- historisch gewachsen
- rechentechnisch einfach
- aber funktional primitive Nichtlinearitäten
Sie erzeugen:
- weiche, unscharfe Aktivitätsprofile
- viele gleichzeitig aktive dyadische Produkte
- Überlagerungen von Mustern
- „verwaschene“ Repräsentationen
- und damit Halluzinationen
Und ein Punkt kommt noch hinzu: Viele KI-Algorithmen (z. B. Transformer) berechnen erst das komplette Matrizenprodukt der ersten mit der zweiten Gewichtsmatrix. Erst danach wird eine Nichtlinearität angewendet. Eigentlich müsste diese Nichtlinearität bereits nach der ersten Matrizenmultiplikation angewendet werden, damit schwache Muster nicht neue Elementarsignale erzeugen, die die Mustererkennung verwaschen.
Zusammenfassung
Halluzinationen in KI‑Systemen entstehen nicht nur durch die rekonstruktive Natur dyadischer Produkte, sondern auch durch die unvollständige Unterdrückung unzutreffender dyadischer Produkte durch die verwendeten Nichtlinearitäten. Da ReLU, Sigmoid, Tanh und Softmax falsche dyadische Produkte nur schwach dämpfen, bleiben viele davon aktiv und mischen sich in die Mustererkennung ein. Die Biologie löst dieses Problem durch laterale Hemmung mit gaußförmigem Verlauf, die unzutreffende dyadische Produkte nahezu vollständig unterdrückt.
Das ist ein Satz, den man in der KI‑Literatur vergeblich sucht – aber er ist mathematisch zwingend.
These der primitiven Nichtlinearitäten
Die KI verwendet primitive Nichtlinearitäten, die Halluzinationen begünstigen. Die Biologie verwendet optimale Nichtlinearitäten, die Halluzinationen verhindern.
Wenn man die Zeilen der ersten Gewichtsmatrix normiert und nach Ähnlichkeit sortiert, entsteht ein stetiger Merkmalsraum. Legt man anschließend eine gaußförmige laterale Hemmung über die stärkste Aktivierung, werden unzutreffende dyadische Produkte effektiv unterdrückt. Dieser Mechanismus ist der biologischen Signalverarbeitung ähnlich und verhindert die verwaschenen Mustererkennungen und Halluzinationen, die durch primitive KI‑Nichtlinearitäten entstehen.
Die Notwendigkeit der ergänzten Elementarsignale
Transformer und ähnliche KI-Systeme nutzen die dreistufige Signalauswertung
- Elementarsignale -> Komplexsignale
- Komplexsignale ->Elementarsignale
- Elementarsignale -> Komplexsignale.
Biologische Systeme verwenden bereits die Elementarsignale der zweiten Ebene. Sie sind darauf angewiesen, die vervollständigten Elementarsignale für ihre motorische Steuerung einzusetzen. KI-Systeme ohne motorische Komponenten (Sprachsysteme) benötigen diese Signale nicht, daher verwenden sie diese auch nicht. Es ist aber absehbar, dass KI-Systeme mit motorischen Komponenten auch die vervollständigten Elementarsignale nutzen werden.
Monografie von Dr. rer. nat. Andreas Heinrich Malczan
Monografie von Dr. rer. nat. Andreas Heinrich Malczan